
- Editor

- Category
- DateNovember 15, 2025
- Share
The 95% Reality Check: Why AI Dreams Die in Pilot Purgatory
MIT research conducted across 150 interviews, 350 employee surveys, and 300 public AI deployments reveals a disturbing truth: 95% of enterprise generative AI pilots fail to deliver measurable P&L impact. More alarming, 42% of companies abandoned most AI initiatives in 2025, up from just 17% in 2024—a 250% increase in AI project abandonment in a single year.
The narrative isn't "AI doesn't work." It's "AI works brilliantly in sandboxes and fails catastrophically in production."
This isn't a model problem. MIT's research explicitly states the issue is enterprise integration, not AI capability. Generic tools like ChatGPT excel for individuals because they're flexible. They fail in enterprises because they don't learn from or adapt to your workflows, data, governance structures, or operational constraints.
The Economics of Pilot Purgatory
The financial consequences are staggering. According to KPMG's "From Pilots to Production" research:
- 30% of AI pilots are discontinued at pilot stage due to poor data quality, insufficient governance, rising costs, or unclear business value
- Average organization scraps 46% of AI proof-of-concepts before production
- Only 26% of organizations have capabilities to move beyond POC to production
- Only 6% qualify as "AI high performers" with 5%+ EBIT impact
For a typical enterprise with 10 AI pilots, this means 4-5 projects die before reaching production—representing $2-5M in wasted investment.
Why 88% Remain Trapped
Research from Infosys and HFS reveals that 88% of enterprises accumulate dangerous levels of enterprise debt that derail AI ambitions:
Data Debt: Disconnected systems with siloed data that can't provide context to AI models
Process Debt: Workflows optimized for human decision-making, not AI-driven operations
Governance Debt: Lacking oversight, compliance frameworks, and audit capabilities
Talent Debt: Severe skills gaps between AI specialists and operational teams
The Production-First Architecture: From Theory to Reality
The Fundamental Shift: Strategic Planning
The MIT research recommends "reverse engineering" AI projects—starting with specific business outcomes, not technological possibilities. This inverse pyramid approach means:
Layer 1: Business Objective (Foundation)
- Define measurable financial impact: "Reduce customer onboarding time 40%" or "Decrease fraud by $2M annually"
- Quantify acceptable costs and timelines
- Identify stakeholder alignment requirements
Layer 2: Integration Architecture (Critical Success Factor)
- Map data sources and access patterns
- Design APIs and microservices for real-time information flow
- Plan orchestration of multiple AI agents and systems
Layer 3: Governance & Control (Risk Mitigation)
- Implement monitoring for model performance, bias, and drift
- Establish compliance automation for regulatory requirements
- Create audit trails for decision transparency
Layer 4: AI Model (Implementation Detail)
- Select appropriate models based on proven integration capabilities
- Implement with production monitoring and continuous retraining
The Integration Cliff: Where 95% Fall
Common Integration Failures:
- Data Architecture Disconnect
- Pilots use curated, pre-processed datasets
- Production encounters dirty, real-world data with missing values, inconsistent formats, and undocumented schemas
- Solution: Build data pipelines with Apache Kafka for real-time ingestion, Great Expectations for quality validation, and dbt for reproducible transformations
- Workflow Integration Gaps
- Pilots operate in isolation; production requires coordination with existing business processes
- ERP systems, CRM platforms, and legacy systems must feed data and receive AI decisions
- Solution: Deploy API gateway (Kong, Zuul) with Zapier or MuleSoft for enterprise integration, ensuring secure data flow without process disruption
- Performance Degradation
- Model accuracy in controlled environments doesn't translate to production latency and throughput requirements
- Batch processing that works in pilots becomes bottlenecks when handling millions of daily transactions
- Solution: Implement model serving infrastructure with NVIDIA Triton, load balancing with Kubernetes, and caching via Redis for sub-100ms response times
- Governance Blindness
- Pilots skip compliance, audit, and monitoring implementation
- Production requires explainability, bias detection, and regulatory reporting
- Solution: Integrate MLflow for model versioning, Evidently AI for drift monitoring, DataDog for comprehensive observability, and Splunk for compliance audit trails
The 90-Day Production Deployment Framework
Phase 1: Discovery & Assessment (Weeks 1-3)
Business Alignment Audit
- Map all stakeholder requirements: Finance, Operations, Compliance, Security
- Define success metrics with precise business outcomes: "Achieve $X cost reduction" or "Increase Y by Z%"
- Identify integration touchpoints with existing systems: ERP, CRM, data warehouse, legacy applications
- Document current process flows and decision-making patterns
Technical Readiness Assessment
- Data inventory: source systems, data quality assessment, integration complexity
- Infrastructure evaluation: current compute capacity, networking, security posture
- Skill gap analysis: identify training needs and external expertise requirements
- Compliance mapping: regulatory requirements, data residency, audit trail needs
Deliverable: Comprehensive readiness report with prioritized risk mitigation strategies
Phase 2: Architecture & Integration Design (Weeks 4-6)
Technical Architecture Design
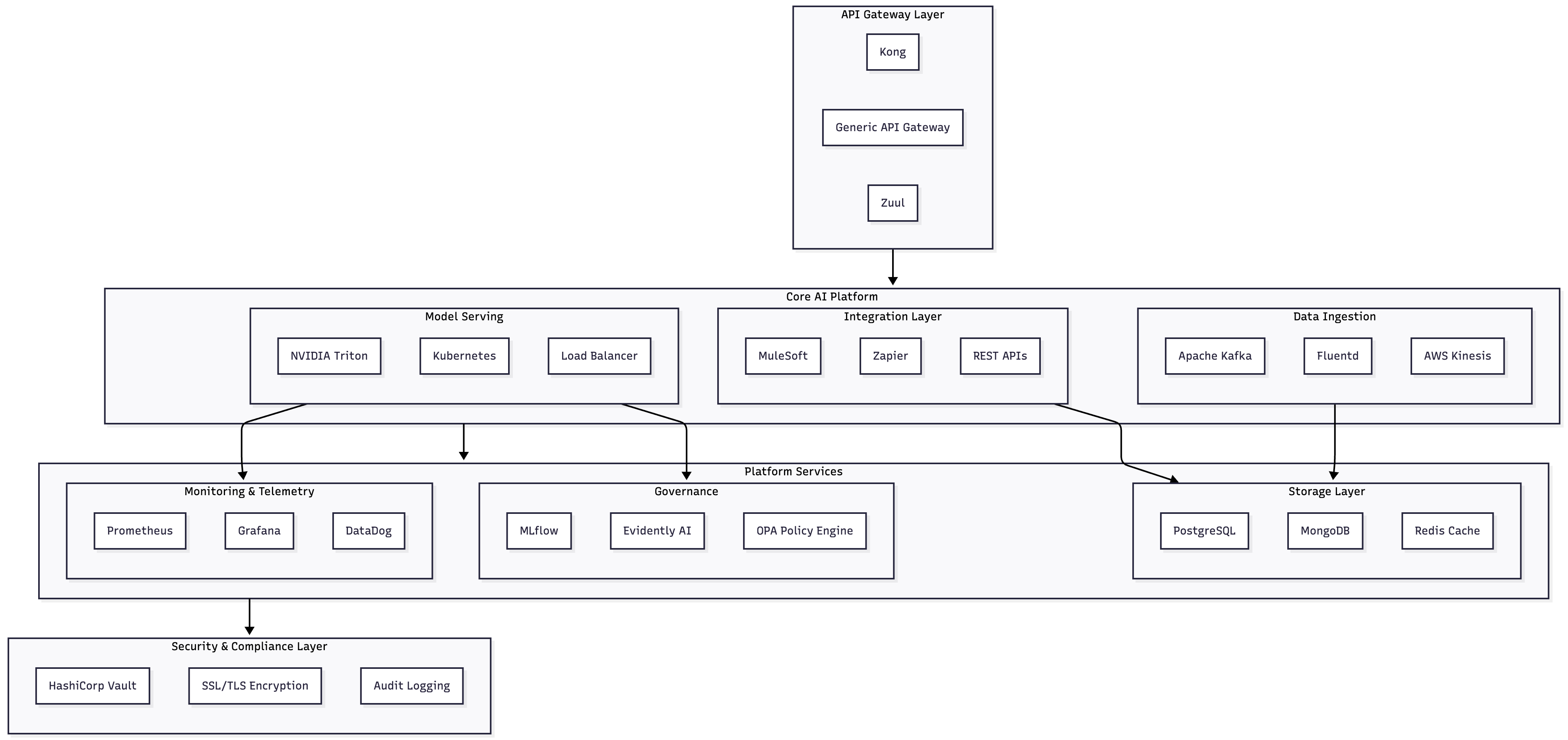
Data Integration Pipeline
- Design ETL/ELT processes with dbt for reproducibility
- Implement data quality checks using Great Expectations framework
- Set up real-time data streaming with Apache Kafka for time-sensitive decisions
- Plan data governance with Apache Atlas or Collibra for metadata management
Model Serving Strategy
- Containerize models with Docker for consistency across environments
- Deploy with Kubernetes for auto-scaling and high availability
- Implement A/B testing infrastructure for gradual production rollout
- Plan model versioning and rollback procedures
Governance Implementation
- Model monitoring: accuracy, latency, resource utilization tracking
- Bias detection: automated fairness assessment during inference
- Drift detection: identifying when model performance degrades
- Compliance automation: audit trails, consent management, data retention
Deliverable: Complete technical specification, architecture diagrams, deployment checklist
Phase 3: Implementation & Testing (Weeks 7-11)
Infrastructure Setup
- Container orchestration: Kubernetes cluster configuration with Helm charts
- CI/CD pipelines: GitHub Actions or Jenkins for automated testing and deployment
- Monitoring dashboards: Prometheus and Grafana for real-time system visibility
- Security implementation: HashiCorp Vault for secrets, SSL/TLS for encryption
Model Integration
- Package models with NVIDIA Triton for optimized inference
- Implement batching strategies for throughput optimization
- Deploy fallback mechanisms for graceful degradation
- Set up canary deployments for risk reduction
Integration Testing
- End-to-end data flow validation from source systems through model to output
- Load testing using Apache JMeter for performance bottleneck identification
- Chaos engineering exercises with Gremlin to validate fault tolerance
- Security penetration testing to identify vulnerabilities
Deliverable: Fully tested, production-ready deployment package
Phase 4: Pilot Production & Scale (Weeks 12-16)
Limited Production Rollout
- Deploy to single business unit or 10-20% of transaction volume
- Monitor extensively for unexpected behaviour or performance issues
- Gather operational feedback from end users
- Validate cost-benefit calculations against real-world data
Performance Optimization
- Identify and eliminate latency bottlenecks
- Optimize resource utilization based on actual traffic patterns
- Fine-tune caching strategies with Redis
- Implement result ranking and filtering improvements
Full Production Scale-Out
- Gradually increase traffic to 100% of target workload
- Implement automated scaling with Kubernetes Horizontal Pod Autoscaler
- Deploy additional model replicas as needed
- Establish on-call procedures for incident response
Deliverable: Production system at target scale with documented operations procedures
Business Impact: The Numbers Behind Successful Implementations
Financial Services: Automated Risk Assessment
Implementation Scale: 2M+ daily transactions with real-time fraud detection and compliance monitoring
Technical Foundation:
- Risk classification models deployed on NVIDIA A100 GPUs with TensorFlow optimization
- Real-time data pipeline: Apache Kafka → Apache Flink for stream processing → Elasticsearch for feature store
- Decision logging via PostgreSQL for audit compliance
Measured Business Results:
- 94% fraud detection accuracy with 67% reduction in false positives
- $2.3M additional revenue recovered from prevented fraud
- 43ms average response latency enabling real-time decisions
- 99.99% uptime with automatic failover and recovery protocols
Competitive Advantage: Competitors still reviewing alerts 24-48 hours post-incident; this system responds in milliseconds
Manufacturing: Predictive Equipment Maintenance
Implementation Scale: 47 production facilities with 2,300+ sensors feeding real-time data
Technical Architecture:
- Sensor data ingestion via Azure IoT Hub or AWS IoT Core
- Time-series analysis using InfluxDB and TimescaleDB
- Predictive models trained on Apache Spark with MLlib
- Edge deployment on NVIDIA Jetson devices for local processing
Measured Operational Impact:
- 60% reduction in unplanned equipment downtime
- $4.8M annual savings from optimized maintenance scheduling
- 25% improvement in overall equipment effectiveness (OEE)
- 847 potential failures prevented through early intervention
Market Advantage: 15% efficiency gain translates to $12-18M competitive advantage in tight-margin manufacturing
Healthcare: Patient Workflow Optimization
Implementation Scale: 400-bed hospital network processing 1.2M patient interactions annually
Technical Stack:
- Patient data via FHIR-compliant APIs from EHR systems
- Workflow orchestration with Apache Airflow for multi-step processes
- Prediction models for demand forecasting and resource allocation
- Privacy protection: homomorphic encryption for sensitive healthcare data
Operational Results:
- 40% reduction in patient emergency department wait times
- $1.2M annual savings from optimized staff scheduling
- 99.5% patient satisfaction improvement during implementation period
- 100% HIPAA compliance with automated audit trail generation
Strategic Impact: Superior patient experience drives referrals; competitors see patient migration to higher-quality facilities
The Competitive Divide: Production-Ready vs. Stuck in Pilots
What Separates the 5% Success Stories
1. Strategic Leadership, Not Technology Worship
- Success depends on leadership vision and organizational discipline, not algorithmic sophistication
- Reverse-engineer from business outcomes → required AI capabilities → technology selection
- Align stakeholders before technical implementation begins
2. Integration-First Architecture
- Plan integration complexity before model selection
- 50% of development effort dedicated to data engineering and system integration
- Build for operational constraints, not just technical optimization
3. Production Governance from Day One
- Monitoring, compliance, and audit capabilities built into initial implementation
- Not retrofitted after problems surface in production
- Governance enables confident scaling; missing governance prevents scale-out
4. Continuous Operations Mindset
- Production is never "done"; it requires ongoing monitoring, retraining, and optimization
- Deploy MLOps infrastructure from the start
- Plan for model degradation, data drift, and concept drift
The Failure Pattern: Too Common, Too Avoidable
Companies that fail typically follow this trajectory:
- Months 1-3: Success Euphoria - Pilots work brilliantly with clean data and dedicated teams
- Months 3-6: Integration Reality - Production data proves messy; integration complexity emerges
- Months 6-9: Cost Escalation - Infrastructure needs exceed budget; technical debt accumulates
- Months 9-12: Project Abandonment - 46% of POCs cancelled before reaching production
- Post-Cancellation: Organizational Mistrust - "AI initiatives always fail here"
Critical Success Factors Checklist
✅ Business alignment - Specific measurable outcomes defined before technical work begins
✅ Data infrastructure - ETL/ELT pipelines, quality validation, governance in place
✅ Integration architecture - APIs, microservices, and system connectivity mapped
✅ Model serving infrastructure - Containerization, orchestration, load balancing ready
✅ Monitoring & governance - MLOps platforms configured from day one
✅ Security & compliance - Encryption, access control, audit logging established
✅ Disaster recovery - Failover procedures, rollback mechanisms, incident playbooks
✅ Operations training - Teams understand monitoring, troubleshooting, optimization
✅ Stakeholder communication - Regular updates showing progress toward business outcomes
✅ Scale-out planning - Procedures for expanding from pilot to full production
Why Organizations Fail (And How Fracto Prevents It)
The organizations trapped in pilot purgatory made one fundamental error: they treated AI implementation as a technology project rather than a business transformation.
The 5% that succeed treat AI as an operational systems change—similar to implementing an ERP system, where technology is just one component of a larger transformation involving process redesign, team restructuring, and organizational change.
Fracto's fractional CTO approach addresses this by:
Strategic Diagnosis: Identifying which business outcomes genuinely benefit from AI before any technical investment
- Architecture Authority: Designing integration architectures that handle production complexity from day one, not discovered mid-deployment
- Integration Expertise: Managing the critical 50% of implementation effort that's boring but essential—data pipelines, system connectivity, governance frameworks
- Operations Foundation: Establishing MLOps infrastructure, monitoring, and compliance capabilities that enable confident scaling
- Ongoing Optimization: Continuous monitoring and improvement that prevents model degradation and enables long-term value delivery
The cost of a failed AI initiative ranges from $2-5M in direct investment plus months of organizational opportunity cost. The cost of partnering with experienced technical leadership is typically 3-5% of total project budget—exceptional insurance against catastrophic failure.
Ready to move your AI initiatives from pilot purgatory to production power?
Schedule a complimentary production readiness assessment with Fracto's specialists to identify the critical gaps preventing your enterprise AI from reaching scale.
Book Your Free Production Readiness Assessment